Nowości w WordStat 7
- Narzędzie ekstrakcji tematu
Wdrożono nowe narzędzie ekstrakcji tematu dokumentu, bazujące na podstawie analizy tekstu, umożliwiające szybkie wyodrębnienie propozycji tytułu tekstu, nawet z dużych zbiorów danych. Uzyskane w ten sposób tytuły mogą być zmieniane, łączone lub usuwane. Panel boczny narzędzia pozwala również porównać częstotliwość występowania konkretnych tematów dla różnych zmiennych wykorzystując wykresy słupkowe i wykresy liniowe.
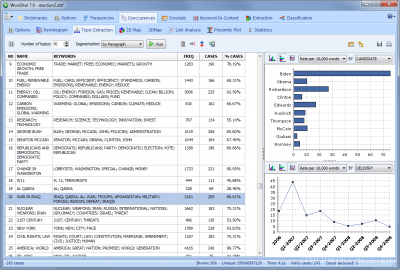
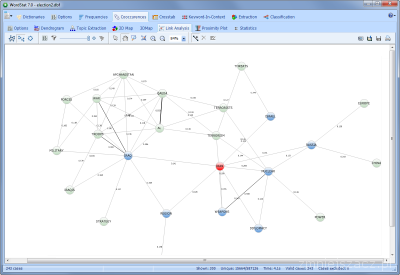
- Analiza połączń tekstów
Nowa funkcja Link Analysis pozwala na wyświetlanie na jednym ekranie wielowymiarowego grafu obrazującego połączenia występujących w tekście. Wykres jest interaktywny i pozwala na eksplorowanie danych w celu zbadania połączeń sekcji tekstu.
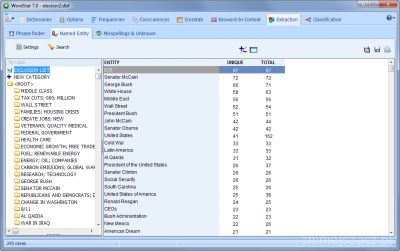
- Ekstrakcja nazw jednostek
Nowa funkcja ekstrakcji nazw jednostek w oparciu o wbudowane wzorce. Nazwy te mogą być dodawane do skategoryzowanego słownika poprzez zastosowanie operacji przeciągnij i upuść.
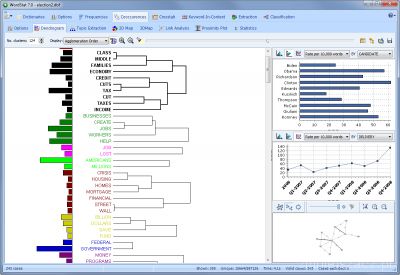
- Ulepszony dendrogram
Podczas grupowania słów kluczowych lub kategorii tekstów, nowy panel po prawej stronie dendrogramu pokazuje rozkład częstotliwości wybranego klastra tekstowego w zależności od jednej lub dwóch niezależnych zmiennych. Pokazywany jest również schemat połączeń.
- Bardziej inteligentne zarządzanie błędami ortograficznymi
Błędy ortograficzne i słowa nieznane są automatycznie dopasowywane do wpisów istniejących w słowniku użytkownika i mogą być też szybko dodawane, jako nowe elementy. Przeprojektowany interfejs rozpoznaje także potencjalne zamienniki słów, jak również wykrywa ewentualne błędy w pisowni wyrazów, które występują w słowniku.
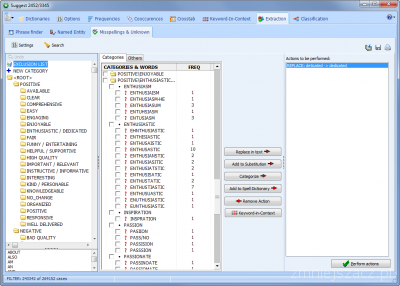
- Ulepszona funkcjonalność słów kluczowych
Strona słów kluczowych (Keyword-in-Context) zawiera teraz widok drzewa słów kluczowych dla danych kontekstowych, posortowanych w kolejności malejącej częstotliwości ich występowania. Widok drzewa może być używany do filtrowania i łatwego poruszania się po długich indeksach tekstu.
- Ulepszona edycja przeciągnij i upuść
Można teraz przeciągać sugerowane słowa (strona częstotliwości) i nakładające się frazy (strona wyszukiwania fraz) bezpośrednio z paneli po prawej stronie do panelu słownika.
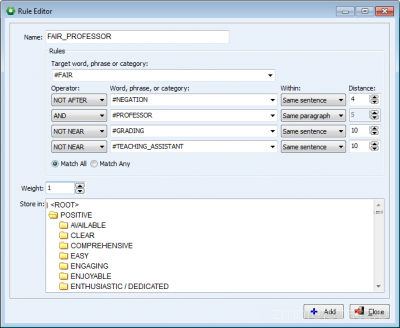
- Lepsze mechanizmy reguł synonimów
Edytor reguł obsługuje teraz do czterech warunków, a każdy z warunków może wykorzystywać inne ustawienia odległości znaczeniowej słów liczonych w jednostkach (dokument, paragraf, zdanie, itd.) i odległości fizycznej (liczba słów).
- Trzynaście wersji językowych
Zaimplementowane 13 wersji językowych słowników terminów pierwotnych (angielski, francuski, hiszpański, włoski, niemiecki, polski, duński, holenderski, fiński, norweski, portugalski, rumuński, rosyjski i szwedzki).
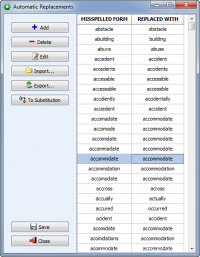
- Podgląd i edycja automatycznego zastępowania słów
Aktualnie można przejrzeć listę automatycznego zastępowania tekstu, edytować wpisy, jak również importować i eksportować tę listę na dysk, pozwalając na udostępnienie listy zamienników innym użytkownikom lub przenieść je na inny komputer.
- Rejestr zmian w słownikach
Rejestry wszystkich zmian wprowadzonych do słowników i list są teraz przechowywane na dysku. Ta właściwość może zostać wyłączona, gdy zachodzi taka potrzeba.
- Import i eksport słowników
Słowniki mogą teraz być importowane lub eksportowane z/do programu Excel, jako zakładki lub terminy oddzielone przecinkami oraz z/do plików XML.
- Ulepszenia wydajnościowe
Ulepszona szybkość. Na przykład, narzędzie ekstrakcji frazy jest od pięciu do 20 razy szybsze, tworzenie listy KWIC dla dużych zestawów danych, których ekstrakcja zajmowała kilka minut, teraz trwa ułamek sekundy.
- Dodawanie notatek do wpisów słownikowych
Możliwe jest załączanie do sześciu typów notatek do słowników. Użytkownik może różnicować komentarze przy użyciu kolorów i etykiet.
- Analiza klastrów i fraz
Nowe przyciski na dendrogramie oraz na stronie wyszukiwania fraz pozwalają na dostęp do okna dialogowego analizy porównawczej zwrotów lub klastrów. Możliwe jest uzyskanie różnych statystyk powiązań (chi-kwadrat, F-test, test Pearsona, itp.), tworzenie wykresów słupkowych, wykresów bąbelkowych lub strefy aktywności oraz przeprowadzanie analiz korespondencji.
- Ulepszona automatyczna klasyfikacja dokumentów
Moduł automatycznej klasyfikacji dokumentu został przeniesiony na własną dedykowaną stronę, dodano też funkcję, pozwalającą optymalizować modele klasyfikacji dla danych porządkowych. Użytkownik może też edytować wartości prognozowanej zmiennej bezpośrednio ze strony podglądu błędów, co pozwala na korygowanie błędnie sklasyfikowanych przypadków w rejestrze danych.
- Ulepszone zarządzanie pamięcią
WordStat umożliwia teraz szybsze przetwarzanie bardzo dużych zbiorów tekstowych.
- Obsługa znaków wieloznacznych we wpisach słownikowych
Słownik wpisów może teraz zawierać symbol wieloznaczny # zastępujący cyfry i nawiasy kwadratowe.
- Ulepszone sortowanie słowników
Możliwe jest sortowanie słowników tylko z podziałem na przedmioty, bez wpływu na kolejność kategorii treści.
- Wybór wielu elementów słownika
Na głównej stronie słowników, możliwe jest zaznaczenie kilku pozycji w słowniku kategoryzacji przy użyciu klawiszy Shift lub Ctrl i przeniesienia, edycji lub usunięcia tych elementów.
- Nowy trójwymiarowy wykres słupkowy
Na stronie CROSSTAB, użytkownicy mogą teraz wybrać jeden z dwóch typów wykresów słupkowych 3D: 3D grupowany lub wykres kolumnowy 3D.
- Nowe formaty osi
Etykiety na dolnej osi wykresów mogą być teraz wyświetlane pod kątem 45 stopni, w pionie lub w poziomie, w jednym wierszu lub w dwóch wierszach.