Nowości w WordStat 8
WordStat 8 posiada nowe funkcje i opcje zwiększające elastyczność, a także pozwalające na używanie tego oprogramowania zarówno przez mniej doświadczonych użytkowników, jak i ekspertów.
Poniżej opisane zostały główne ulepszenia i nowości w pakiecie WordStat 8.0
Aktualnie możliwe jest tworzenie projektu w samym WordStat z różnych źródeł, którymi mogą być:
Rozróżnianie wielkości liter: słowniki kategoryzacji i lista wykluczeń obsługują teraz wpisy uwzględniające wielkość liter, aby ujednolicić takie słowa, jak "Bill" i "bill", "Buck" i "buck" lub "us" i "US".
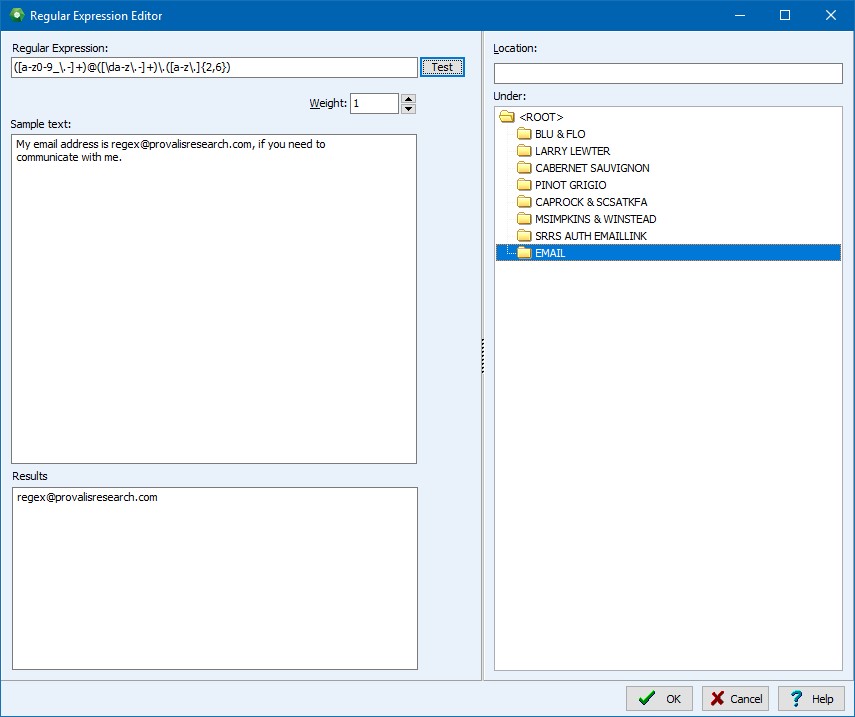
Wyszukiwanie wyrażeń regularnych (Regex): stworzono edytor wyrażeń regularnych, w którym można tworzyć własne formuły Regex, celem szybkiego wyodrębniania określonych informacji z danych tekstowych, takich jak adresy e-mail lub kody pocztowe.
Nowy proces zastępowania: ulepszono proces zastępowania, dzieląc go na dwie części. Oddzielając go od procesu lematyzacji, można łatwo śledzić substytucje i utrzymywać słownik treści niezależnie od błędnie napisanych słów.
Listy wykluczeń i zastępczych wraz ze słownikiem kategoryzacji można teraz zapisać w pliku modelu kategoryzacji. Ten plik może być używany w innych projektach WordStat, a także w QDA Miner, WordStat Document Explorer lub w SDK.
WordStat 8 WordStat 7
 WordStat 8 otwiera naukowcom zajmującym się danymi NLP możliwość do używania skryptów Python i jego pełnego zakresu bibliotek open-source do wstępnego przetwarzania lub przekształcania dokumentów tekstowych do analizy w WordStat. Ta nowa funkcja zwiększa elastyczność programu WordStat i umożliwia użytkownikom programowanie w języku Python.
WordStat 8 otwiera naukowcom zajmującym się danymi NLP możliwość do używania skryptów Python i jego pełnego zakresu bibliotek open-source do wstępnego przetwarzania lub przekształcania dokumentów tekstowych do analizy w WordStat. Ta nowa funkcja zwiększa elastyczność programu WordStat i umożliwia użytkownikom programowanie w języku Python.

Poniżej opisane zostały główne ulepszenia i nowości w pakiecie WordStat 8.0
1. Standalone Text Mining Platform
Nauka obsługi nowego oprogramowania z wieloma funkcjami może być zniechęcającym zadaniem. Wcześniej WordStat był dodatkowym modułem do programu QDA Miner – skonfigurowanie projektu wymagało nie tylko znajomości obsługi WordStat, ale także elementów programu QDA Miner. WordStat 8 jest teraz samodzielnym produktem. Ogranicza to złożoność i krzywą uczenia się, ponieważ użytkownicy mogą teraz tworzyć swoje projekty bezpośrednio w programie WordStat. Jednak pakiet w dalszym ciągu może być uruchamiany jako moduł dodatkowy do QDA Miner, STATA lub SimStat.Aktualnie możliwe jest tworzenie projektu w samym WordStat z różnych źródeł, którymi mogą być:
- Dokumenty: MS Word, RTF, PDF, HTML, itp.
- Pliki danych: Excel, CSV, Stata, itp.
- Platformy ankiet internetowych: SurveyMonkey, Qualtrics, SurveyGizmo, itp.
- Narzędzia do zarządzania bibliografią: Endnote, Zotero, Mendeley
- Serwisy społecznościowe: Twitter, Facebook, Reddit, RSS Feeds, Youtube
- Emaile: Outlook, Gmail, Hotmail, Mbox i format EML
- Wiele innych źródeł…
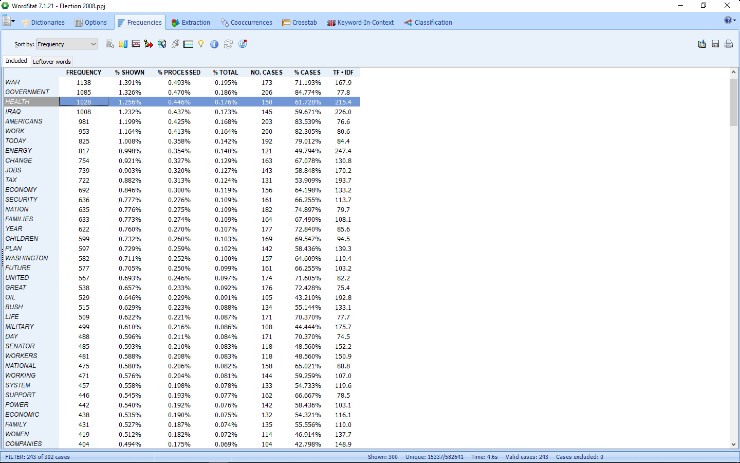
2. Nowy tryb Explorer Mode
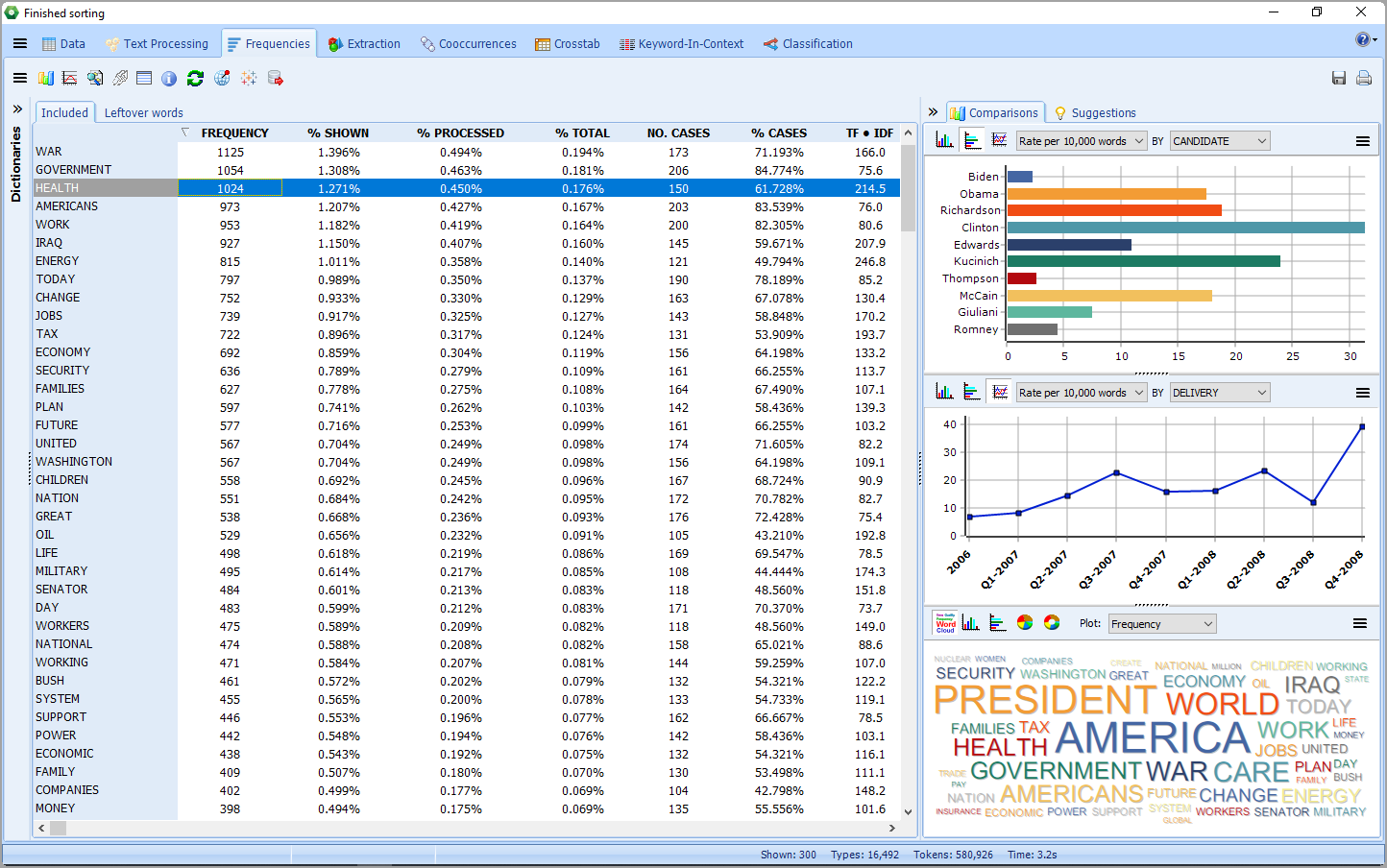
Został zaimplementowany nowy tryb Explorer, który umożliwia Użytkownikom z małym doświadczeniem w analizie danych tekstowych, szybkie i łatwe wydobycie znaczenia z dużej ilości danych. Dzięki ulepszonemu narzędziu do modelowania tematów, w programie WordStat 8 można zidentyfikować najczęstsze słowa i wyrażenia oraz wyodrębnić najbardziej istotne tematy w swoich dokumentach. W dowolnym momencie można przejść do trybu expert mode, który zapewnia dostęp do wszystkich funkcji programu WordStat, w tym słowników analizy treści , funkcji zestawień tabelarycznych i analizy współwystępowania.3. Ulepszone modelowanie tematów
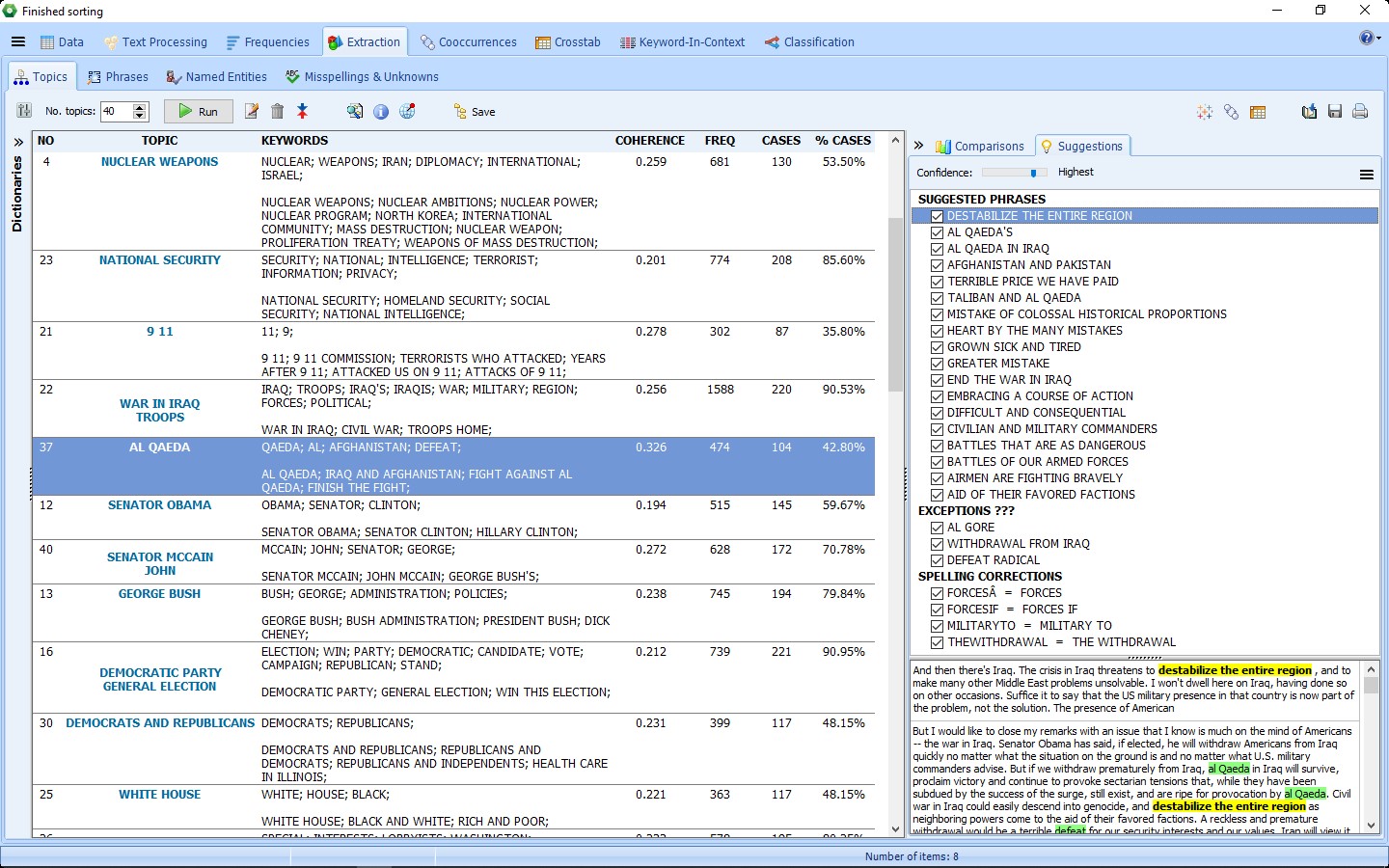
Istniejąca procedura modelowania tematów korzysta z wielu ulepszeń, takich jak dodatkowy algorytm wyodrębniania (NNMF), który przyspiesza wydobywanie tematów, a także innowacyjny proces wzbogacania tematów. Technika ta pozwala wyjść poza rozwiązania typu “bag-of-word”, typowe dla tradycyjnego modelowania tematycznego, poprzez automatyczne wybieranie powiązanych fraz i dostarczanie sugestii dotyczących dodatkowych wyrażeń, potencjalnych wyjątków, a także poprawek pisowni. Wszystkie te innowacje powinny prowadzić do bardziej precyzyjnego i wszechstronnego pomiaru istotnych tematów w zbiorze tekstów.
4. Nowe ulepszone tworzenie grafiki
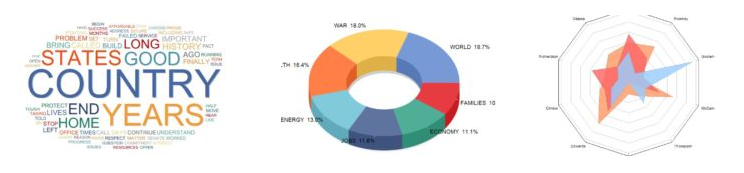
WordStat 8 ma zawiera nowe możliwości wyświetlania grafik, które pomagają lepiej zrozumieć wyniki analizy danych. Producent udoskonalił interaktywne chmury słów, wykresy pączkowe i radarowe. Za pomocą jednego kliknięcia można również wyeksportować wyniki do oprogramowania Tableau, aby móc korzystać z zaawansowanych narzędzi do interaktywnej wizualizacji danych.
5. Ulepszenia w budowaniu słowników analizy treści
Wprowadzono kilka nowych funkcji i ulepszeń w sekcji słowników kategoryzacyjnych, aby pomóc być bardziej precyzyjnym w wyszukiwaniu tekstowym i uzyskiwać dokładniejsze wyniki.Rozróżnianie wielkości liter: słowniki kategoryzacji i lista wykluczeń obsługują teraz wpisy uwzględniające wielkość liter, aby ujednolicić takie słowa, jak "Bill" i "bill", "Buck" i "buck" lub "us" i "US".
Wyszukiwanie wyrażeń regularnych (Regex): stworzono edytor wyrażeń regularnych, w którym można tworzyć własne formuły Regex, celem szybkiego wyodrębniania określonych informacji z danych tekstowych, takich jak adresy e-mail lub kody pocztowe.
Nowy proces zastępowania: ulepszono proces zastępowania, dzieląc go na dwie części. Oddzielając go od procesu lematyzacji, można łatwo śledzić substytucje i utrzymywać słownik treści niezależnie od błędnie napisanych słów.
Listy wykluczeń i zastępczych wraz ze słownikiem kategoryzacji można teraz zapisać w pliku modelu kategoryzacji. Ten plik może być używany w innych projektach WordStat, a także w QDA Miner, WordStat Document Explorer lub w SDK.
6. Ulepszony interfejs
Ulepszony interfejs umożliwia szybki dostęp i porównywanie wyników, dzięki czemu można uzyskać cenne informacje w kilka sekund.
WordStat 8 WordStat 7
7. Przekształcanie tekstu za pomocą skryptów Python
8. Analiza emotikonów
Emotikony stały się wszechobecne w mediach społecznościowych, wiadomościach tekstowych, e-mailach i innych środkach komunikacji elektronicznej i często są używane do reprezentowania obiektów, wyrażania idei lub sentymentów lub dodawania niuansów do pisemnych wiadomości. Często są integralną częścią wiadomości i trudno ją zignorować. WordStat 8.0 może przekształcić emotikony w ich reprezentację tekstową, co pozwala analizować je samodzielnie lub jako część całej wiadomości.
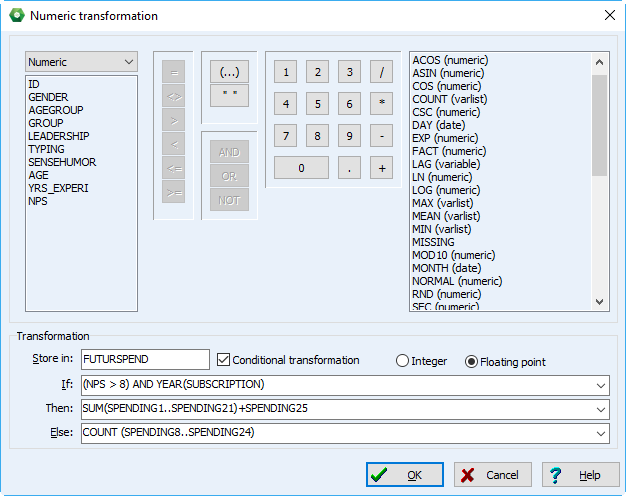
9. Transformacje numeryczne
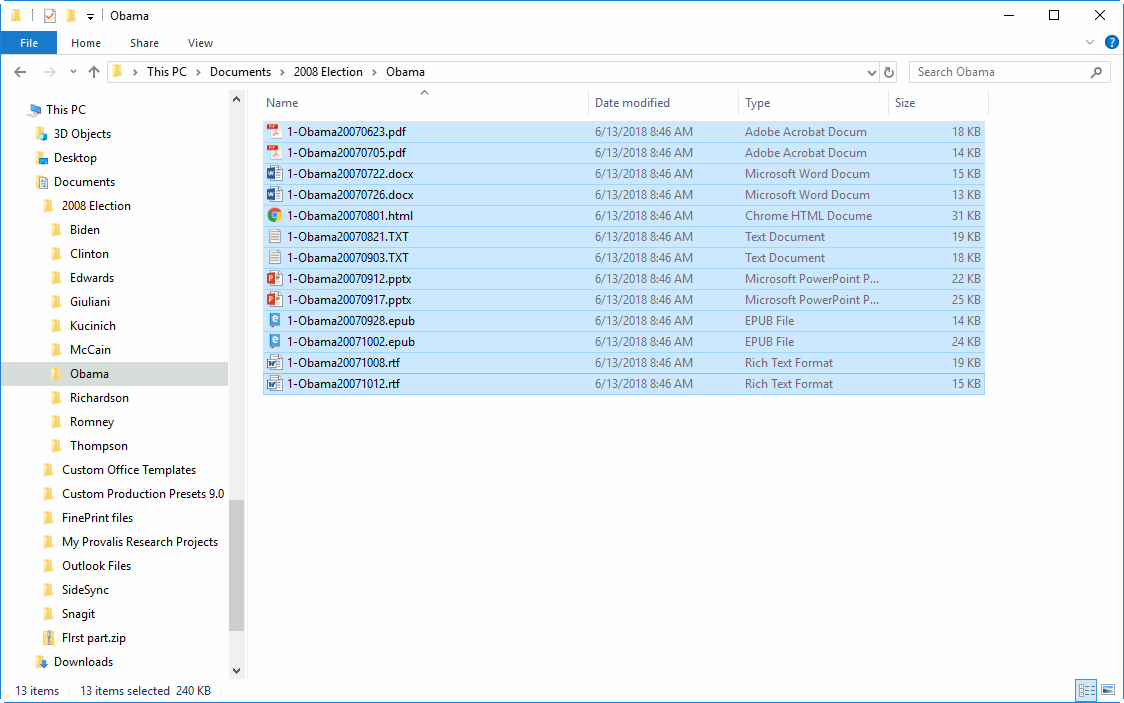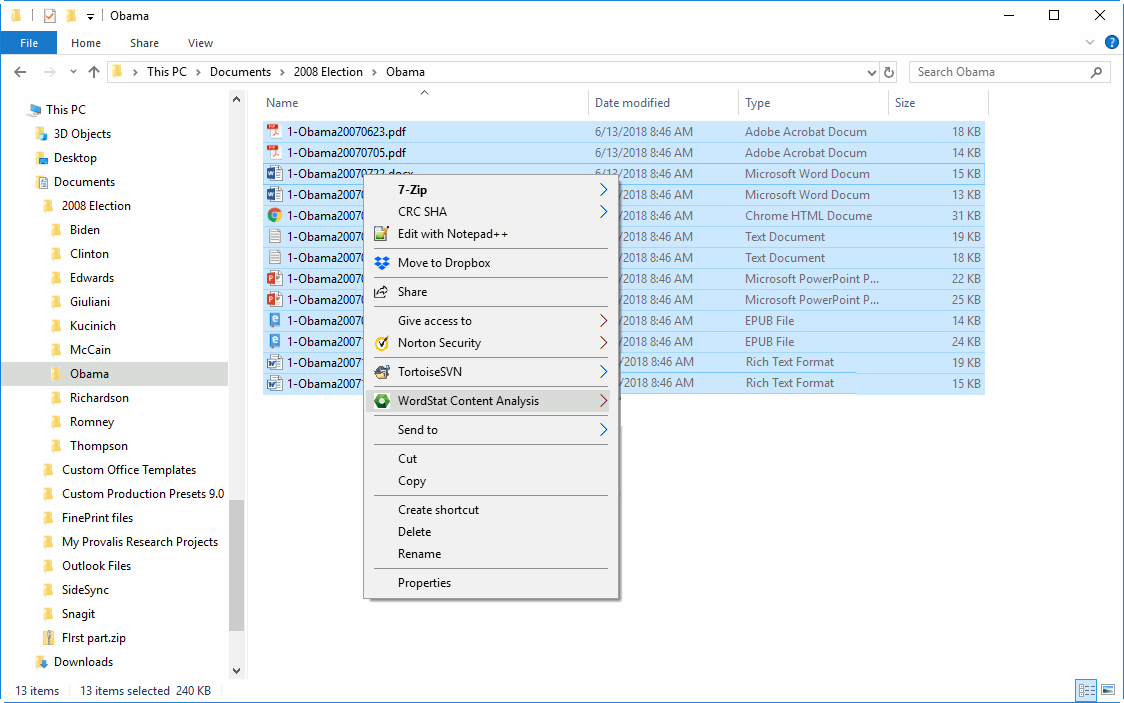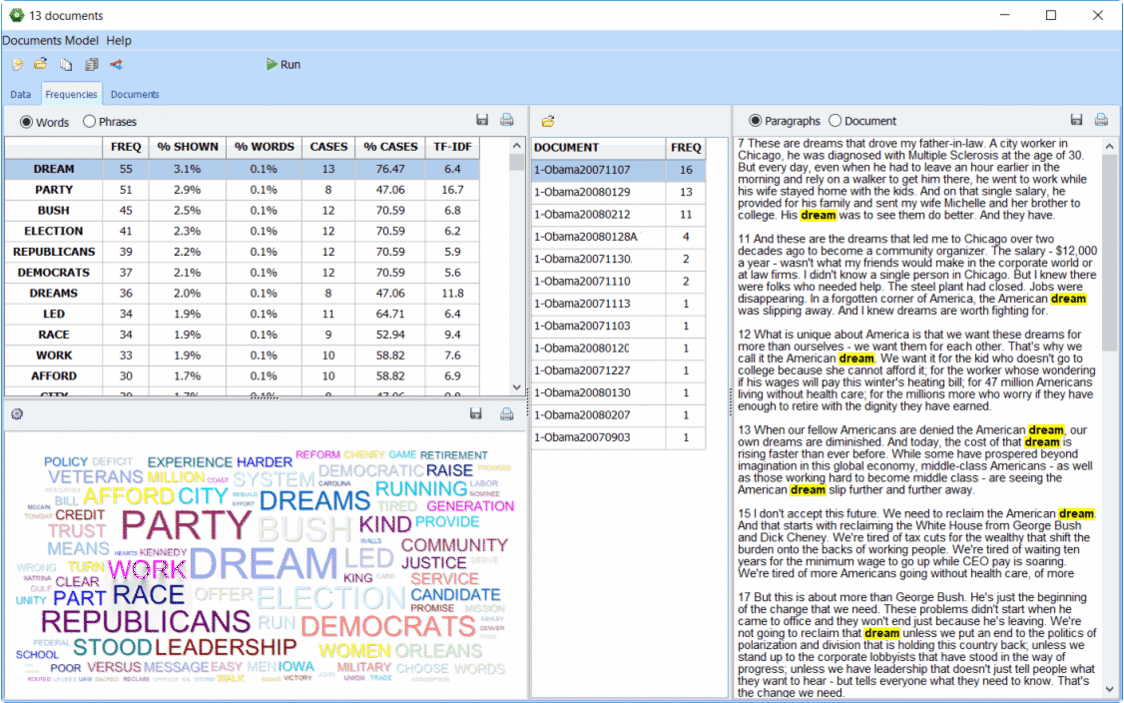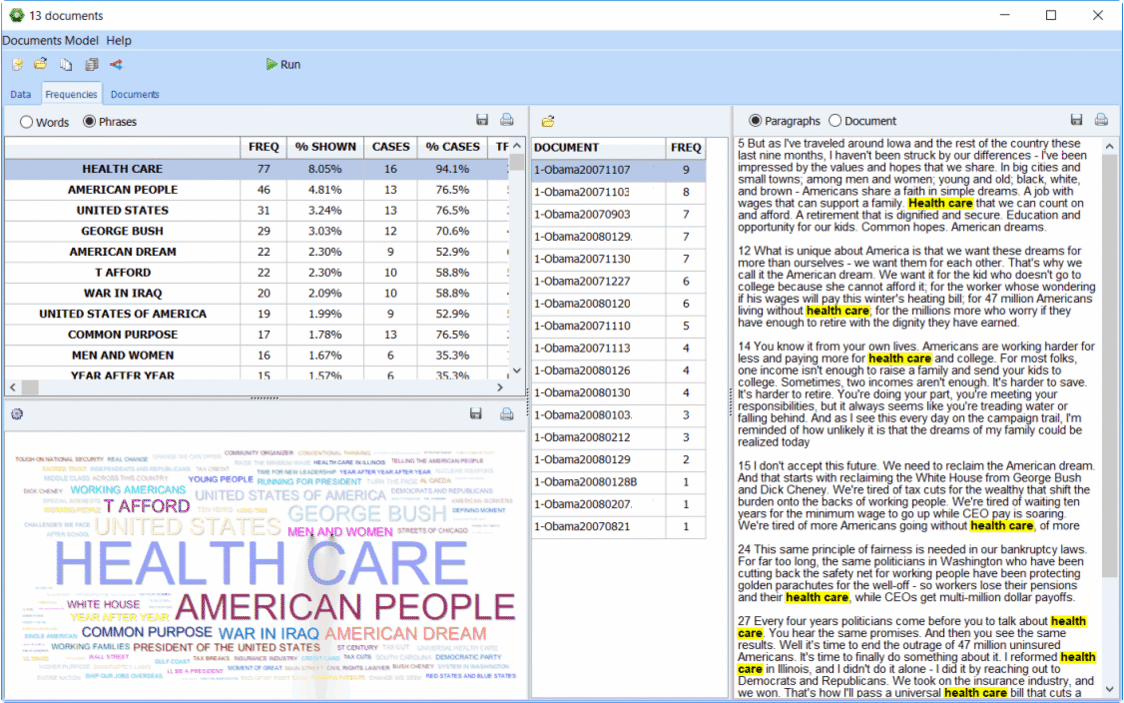
W programie pojawiło się nowe okno dialogowe transformacji numerycznych. Pozwala ono dokonywać obliczeń zmiennych na bazie innych zmiennych, z użyciem prawie pięćdziesięciu funkcji, włącznie z trygonometrycznymi, statystycznymi. Możliwe jest też stosowanie transformacji warunkowych z użyciem struktury logicznej IF-THEN-ELSE (jeśli-wtedy-inaczej).10. Obsługa dokumentów bezpośrednio z okna Windows Explorer
Nowe narzędzie Document Explorer pozwala użytkownikom szybko eksplorować zawartość swoich dokumentów z eksploratora okien bez konieczności importowania dokumentów lub tworzenia projektu. Wystarczy wybrać dokumenty, które mają zostać zbadane, lub folder, który je zawiera, kliknąć prawym przyciskiem myszy i wybrać Eksploruj, aby szybko zidentyfikować najczęstsze słowa i wyrażenia oraz ich położenie w dokumentach. Za pomocą prostego kliknięcia prawym przyciskiem myszy można również przeprowadzić przeszukiwanie semantyczne dokumentów przy użyciu istniejącego słownika kategoryzacji lub klasyfikować dokumenty za pomocą modelu predykcyjnego w programie WordStat.